
Analysing audiovisual data
These pages provide information relating to the analysis of audio visual data using CAQDAS packages. These materials are derived from Qualitative innovations in CAQDAS (QUIC) work on audiovisual analysis.
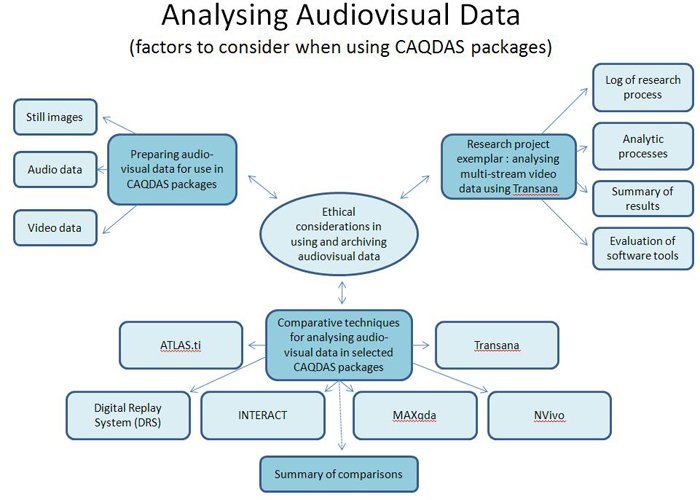
Here you can access information about preparing audio-visual data for use in CAQDAS packages, comparative discussions about using particular packages for audio visual analysis and discussions on the ethical implications of using and archiving audio visual data. In addition is a variety of information about and reflections upon one of QUIC's research projects which analysed multi-stream video data using the software package Transana.
Preparing data for use in CAQDAS packages
In the following sections, we discuss preparing and using different types of multimedia data with various CAQDAS packages:
- Using multimedia data in CAQDAS packages (codecs, streaming, synchronising)
- Preparing different file formats for the use in CAQDAS packages (images, audio files, video files)
- Work-arounds for potential problems, when working with multimedia files in CAQDAS packages.
We start by outlining general information about digital media data including aspects of codecs, streaming and synchronising. After a general introduction we will discuss preparation tasks (the issue of collecting data, aspects of editing including synchronisation of multiple media files, and data handling in different CAQDAS packages) for each file format separately: image, audio and video. See ‘further resources’ for links to related topics and sources.
Note
The advice given here is by no means fully exhaustive but should provide a starting point for planning for the analysis of multi-media data using CAQDAS packages. We do not cover specific software tools or analytic procedures for analysing multi-media data, although there are some comparative functionality tables in the sections on images, audio and video files.
This section discusses the preparation of still images for use with CAQDAS packages by addressing issues of collection, editing and working with still images. Still images are probably the easiest multimedia files to be handled by any CAQDAS package, however some issues arise which are worth considering at the outset of a project.
Working with images
CAQDAS programs have different capabilities for handling images. For example, Transana does not directly support still images, but you could create a video out of a selection of still images for analysis. DRS, which focuses on the analysis of heterogeneous data over time, will allow you to link images to a time line. Most other CAQDAS packages have more standard image analysis functions which are summarised in Table 1.
Table 1: Comparative functionality of selected tools for handling image files in CAQDAS packages
Image files | Zoom | Code a whole image file | Code sections of an image file | Apply annotations/memos to images | |
|---|---|---|---|---|---|
ATLAS.ti 6.1 | all major formats are supported | yes, some resampling | yes | yes, rectangular selections of an image can be coded | yes |
DRS 1.0 | all major formats are supported | yes, but no resampling filter | yes | no | no |
HyperRESEARCH | all major formats are supported | no, fixed size | yes | yes, rectangular selections of an image can be coded | yes |
MAXqda 10 | all major formats are supported | yes, but no resampling filter | yes | Yes, rectangular selections of an image can be coded | yes |
NVivo 8 | all major formats are supported | size depends on window size, no resampling filter, full image is always shown | yes | Yes, rectangular selections of an image can be coded | yes |
QDA Miner 3.2 | all major formats are supported | yes, but no resampling filter | yes | Yes, rectangular selections of an image can be coded | no |
Qualrus | all major formats are supported | no, fixed size | yes | Yes, rectangular selections of an image can be coded | yes |
Transana 2.3 | no | Not applicable | no | no | no |
Collection issues for still images
There are several ways of using and reusing still images for research purposes, each of which involves different issues: collecting one’s own images, reusing existing still images and using images taken by participants. Using data collected by the researcher is probably the easiest way of making sure that the requirements of data size, format etc. meet the research purpose, thus involving the least difficulties in preparing data. However, reusing existing still images, for instance those harvested from the internet might require further editing as the picture resolution might be too high or too low or the colours not strong enough for analytical purposes. This might also be the issue when using pictures taken by participants, although doing so might add another analytical level and therefore be of advantage. Still images taken with a mobile phone are likely to result in a low resolution, thus might not be usable for further detailed analysis. Cell phone cameras and web cams usually do not yet go beyond 5 megapixels, which at times will result in fairly pixilated images. Digital devices with more than 5 megapixels should allow good quality and higher resolution suitable for further research purposes.
Harvesting images from existing data sources does not usually cause problems. Most internet browsers (Internet Explorer, Safari, Firefox, Opera, Konquerer, Google Chrome) allow images to be saved through right-clicking on the picture. Some websites attempt to disable this feature, but you can always view the source code (in most browsers under View ® Source) to find the address of a picture, which you then to paste into your browser's URL bar.
Editing still images
Preparing still images for further usage in a CQADAS program might require further editing, either to rectify insufficiencies or to improve the picture quality. CAQDAS programs do not always allow efficient zooming, resizing or rotating, thus using an image editor to enlarge or otherwise manipulate an image before working on it might be beneficial in the long run. Figure 1 illustrates the dramatic effect which can be achieved to improve picture quality by brightening an image.
The needs of a particular research project will determine the appropriateness of editing images prior to analysis, but it might be useful to sharpen a picture to identify details, or, to enlarge (parts of) a picture. Depending on the size of the picture resizing can also lead to lower resolution.
There are a wide variety of image editors from which to choose:
- Paint - Microsoft’s built in editor is a commonly used picture editor, although it is quite rudimentary
- Picasa - Google has developed this functional freeware image storage and simple editor
- Adobe Photoshop - this proprietary program is a common commercial package for picture editing
- Irfanview - this freeware editor performs the functions most social researchers will need for their analysis, and it has a very intuitive interface
- GIMP - this freeware is more versatile than Irfanview or Picasa, but its interface is consequently much more cluttered
- iPhoto - an image storage system and photo editor for Apple systems.
This section discusses how to prepare audio files for use in CAQDAS packages, including the following aspects: suitable audio file formats; converting audio files; collecting audio data; editing audio data; and data handling of audio data in different CAQDAS packages. For a more detailed technical description on best practices in using digital audio data, please consult the digital audio best practices section.
Handling audio data
Apart from the fact that different CAQDAS packages have different functionalities with respect to the handling of audio files, they also have different approaches for dealing with audio data. The following table overviews the audio file capabilities for selected CAQDAS packages.
Table 2: Comparative functionality of selected tools for handling audio files
Audio file formats | Handle text files independently of audio files | Code audio files directly (i.e. without need for transcript) | |
|---|---|---|---|
| ATLAS.ti 6.1 | all major formats supported where codecs are installed | yes | yes |
| DRS 1.0 rc-7 | all major formats supported where codecs are installed | yes | yes |
| HyperRESEARCH 2.8 | all major formats supported where codecs are installed | yes | yes |
| MAXqda 10 | all major formats supported where codecs are installed | yes | No |
| NVivo 8 | all major formats supported where codecs are installed | yes | yes |
| QDA Miner 3.2 | Not supported | yes | n/a |
| QDA Qualrus Miner 3.2 | all major formats supported where codecs are installed | yes | Yes |
| Transana 2.3 | all major formats supported where codecs are installed | yes | No |
Accepted audio formats
The easiest option would be to collect data in the format you want to store it in, but numerous converters are available if this is not possible. The most important audio codecs and file formats are:
- Waveform (WAV) - wav is the most basic audio format; it produces the best audio quality and is suitable for all CAQDAS packages that process multimedia data. Its main drawback is bulky file sizes. However, as the availability of disk space and bandwidth increases this becomes less of a problem.
- MPEG-1 audio layer 3 (mp3) - mp3 is the most common compressed propriety format, for which a number of free converters into wav are available. The quality of mp3 files varies with their compression and frame rates. Usually, frame rates of 128kpbs and more achieve CD quality. CAQDAS programs that accept multimedia files, will accept most mp3 files.
- RealAudio Media (rm, sometimes also abbreviated ram) - Real Networks' proprietary format, which is difficult to handle in most CAQDAS packages. It should therefore be converted into the more standard mp3 or wav formats, before it is used in those programs.
- OGG Vorbis - ogg is an open source format for compressed audio files. It is nevertheless fairly uncommon. It offers, however, better quality and higher compression than mp3, and is fairly well suited for CAQDAS packages as well. If you reject the wav format for reasons of disk or memory space, this is a good alternative.
- Windows Media Audio (WMA) - wma is Microsoft's standard format for audio compression. A number of different plug-in codecs are available for this format. Hence, compatibility with CAQDAS packages varies more than with other compression formats, which means that, if you can use a particular wma file in the program that you are working with, not necessarily all other files of this type will be supported. Thus, files of this type are better converted.
- Advanced Audio Coding (AAC) - Apple's proprietary compression format aac works best in the Apple environment. It is accepted by most CAQDAS programs that accept multimedia, but you might want to consider converting it, if you work in a Linux or Windows environment.
Audio converters
Not all CAQDAS packages process all types of audio files, so at times it is necessary to convert files to a specific audio format. Various audio file converters exist, including the following:
- Switch - Switch in its freeware version allows you to convert most common audio files except for AACplus into wav or mp3.
- CyberPower converter - this alternative freeware converter allows you to convert the most common audio data formats except aac.
- AVS audio converter - AVS audio converter converts audio between various formats: WAV, PCM, MP3, WMA, OGG, AAC, M4A, AMR and others. Add text information to your audio files.
Collection issues for audio files
Collecting audio data can be undertaken in different ways and thus produce different file formats, e.g. audio recorded with a tape recorder, audio recorder with a digital recorder, audios recorded with a microphone or without a microphone, audios recorded with a mobile phone. For instance, data that has been recorded with a tape recorder and then put on a CD might have to be converted into a wav or mp3 file, which the above converters might be helpful. Additionally, audio data not collected by the researcher him or herself might have been recorded in a different format or include unnecessary information in the beginning and so need to be converted and edited.
In contrast, audio data retrieved from the internet can often be used in CAQDAS packages without any conversion. However, streamed audio files would also need to converted by a recording system in order to be downloaded and saved properly.
Audio editing
Whether self-created or harvested, not all audio files will meet the requirements for an effective analysis. In such cases several audio editors exist. These editors allow noise reduction, cutting sections, splitting files, merging files etc. in order to prepare the audio file in the most effective way for further analysis. Audio editors range from commercial solutions such as Adobe Audition. to freeware editors like Audacity. Other sound editors include Bias Peak and Sony Sound Forge, both commercial, as well as the open source program Ardour (for OS-X and Linux). If financial restraints are not an important issue, however, any editor will facilitate complicated tasks such as noise reduction.
- Adobe Audition - Allow recording and mixing of multiple audio fies, as well as editing, converting and mastering audio files. It is a very useful software easy to use but commercial.
- Audacity - Audacity® is free, open source software for recording and editing sounds. It is available for Mac OS X, Microsoft Windows, GNU?linux, and other operating systems.
- AVS Audio Editor - AVS Audio Editor edits audio collections, records audio data, cnverts between all popular audio formats, applies effects and filters. It is a very useful tool and freeware.
- NCH WavePad - WavePad is an audio editing software that allows cutting, pasting, copying parts of audio recording. It is especially useful when splitting data into smaller sequences in order to reduce file size.
Noise reduction
A common problem is that an audio file might contain too many distractions - noise - in its recording; for instance, the humming of an air conditioning unit, a TV running in the background or car traffic. In some cases these background noises might be part of the analysis whereas in other cases these might be completely redundant. It is therefore worthwhile to consider these aspects before carrying out a noise reduction task (Hall et al., 2008). However, noise removal effects are by no means perfect and can create sound artifacts that themselves are distracting, which may prompt you to use noise reduction effects sparingly (Clukey, 2006).
Splitting
There may be a number of reasons to split audio files into shorter clips especially if only parts of an audio file are of analytical interest. The audio editors mentioned above can help to select the sequence in the audio file, extract it in order to edit it further or even convert it into a different file format.
Synchronising
In contrast to splitting data it might also be suitable to merge two audio files by synchronising them, for example, where two audio files have been recorded at different locations but represent the same event. This might require exact synchronisation which most CAQDAS packages do not support very well, except Transana and DRS. However, it might be more efficient to perform this task upfront using an audio editor.
Separating sources
Separating sources might be applicable if an audio file has different speakers, for instance each recorder with a different microphone. Separating different voices might be useful for the purpose of analysis to detect overlapping talk, possibly even with different volume.
This section discusses the preparation of video data for the use in CAQDAS packages by looking at supported file formats, converting video data, collecting issues for video data, editing video data and the handling of video data in different CAQDAS packages.
Handling video data
The CAQDAS packages that handle video data offer different features for working with and storing data. Table 3 gives an overview of the video file capabilities for the different CAQDAS packages.
Table 3: Comparative functionality of selected tools for handling video files
Video file formats | Handle text files independently of video files | Time-based synchronicity of multiple video files | Code video files directly (i.e. without need for transcript) | |
|---|---|---|---|---|
| ATLAS.ti 6.1 | all major formats supported where codecs are installed | yes | No | yes |
| DRS 1.0 rc-7 | all major formats supported where codecs are installed | yes | yes | yes |
| HyperRESEARCH 2.8 | all major formats supported where codecs are installed | yes | No | yes |
| MAXqda 10 | all major formats supported where codecs are installed | yes | No | No |
| NVivo 8 | all major formats supported where codecs are installed | yes | No | yes |
| QDA Miner 3.2 | Not supported | yes | No | n/a |
| Qualrus | all major formats supported where codecs are installed | yes | No | yes |
| Transana | all major formats supported where codecs are installed | No | yes | No |
Accepted video formats
Similar to audio data, the best way is to initially save the video data in a format that is useful for further use in any CAQDAS package. However, this often might not be possible and additional converting is required. Several converters are available to do so:
- Any Video Converter - freeware
- AVS Video Converter - the most versatile batch converter for videos. This website offers several AVS converters, but the packages are not free.
- Prism - a commercial video converter for both Windows and Apple systems
- Handbrake - a freeware converter, which converts from many codecs into a number of standard formats.
It is recommended to install the relevant codec before working with video files using CAQDAS packages. It may also sometimes be necessary to install the software package the recording device (i.e. video camera) comes with as some video devices only allow viewing and editing data if the related software package is installed on the computer beforehand.
Collection issues for video data
Collecting video data can be undertaken in different ways similar to collecting still images or audio files. JISC’s moving images resource gives advice for basic guidelines on how to create your video files. As mentioned above many video files harvested from the internet can be either straightforwardly used in CAQDAS packages if non-streamed video files or only need to be converted in order to be imported or assigned to CAQDAS programs. In contrast, streamed video files, collected from website like youtube, need to be converted by special recording systems as outlined in the section codecs.
Editing
It may be necessary to edit video data before saving for use in your chosen CAQDAS package. For example, if there is a lot of superfluous material not required for the analysis, where there is a need to synchronise multiple video files or where there are data distortions which require rectification. A wide variety of video editing software packages exist. Common options include:
- Adobe Premiere - Premiere is a widely used video editing program; it performs all the tasks you might want, but is not free.
- Avidemux - Avidemux is not as user-friendly as Premiere, but it is commonly used and is a versatile freeware video editor.
- iMovie - With iMovie, you can label clips - or parts of clips - as "favorite" or "rejected", tag video with preset or custom keywords, then filter your entire library by rating and/or keyword.
- Quick Time Player Pro - QuickTime 7 Pro, allows converting media files to different formats and record and edit them.
Editing tasks for video files
Most editors include a range of features which may be relevant to preparing video data for analysis. These include filters for sharpening video and extracting specific frames or zooming. Extracting specific frames can be useful where specific details warrant a separate analysis. Likewise, the zooming feature might help identifying certain details in videos. The Avidemux manual provides useful comment on how to cut videos.
Synchronising
In contrast, it might be the case that several video files have been collected from the same event, perhaps different camera angles, for example, but need to be viewed and analysed simultaneously. Quick Time Player Pro allows the synchronising of multiple video files. Alternatively, Transana and DRS also enable users to synchronise multiple video files however, this might result in quality loss and slow down the program. Thus, it may be more efficient to synchronise video files before analysing them.
Research project exemplar
QUIC’s work on analysing visual data provides technical guidance for the preparation of audio, video and still image files for analysis with CAQDAS packages, a set of pages on comparative techniques for analysing audiovisual data in various CAQDAS packages (including Transana), some guidance regarding ethical considerations in using and archiving audiovisual data, and outputs stemming from an exemplar project in which the research process is documented. It is these latter outputs that are introduced here.
As outlined in choosing software and the pages on analysing audiovisual data, Transana allows for analysis of multi-stream video data and is a low-cost open-source software. We have chosen it as the CAQDAS package for the exemplar research project since it is an example of currently supported software that is specifically designed for analysis of audiovisual data. Yet Transana is by no means the only CADQAS package that can analyse this type of data, as the pages on comparative techniques for analysing audiovisual data in various CAQDAS packages outline. The pages here are designed to document the processes and outcomes of a research project specifically analysing multi-stream audiovisual data, making Transana an appropriate choice of software. The material is designed to be useful to Transana users, but also to researchers interested in hurdles and analytical choices common to the research process in the context of audiovisual data analysis in CAQDAS packages more generally. The material seeks to provide an insight into the first-hand experience of the researcher on the exemplar research project, as well as discussing the analytical processes that were followed throughout the project. These materials help to contextualise the reported substantive findings of the project. The materials also cover an overall evaluation of the software tools provided in Transana.
In summary, the outputs and guidance from the exemplar research project consist of the following:
- A brief background to the exemplar research project
- The research process in the form of a researcher’s log (approaches, data management, difficulties, solutions etc.)
- The analytical processes that were adopted in the research project (methodological approach, data annotation and coding, search and retrieval techniques).
Please note that this material relates particularly to Transana as a software tool, exploring some of the available analytic procedures for analysing multi-media data. It is not a step-by-step guide or an exhaustive overview of Transana’s features. For general information about Transana functionality see the software review. The outputs from the exemplar project do not reflect on comparative functionality with other CAQDAS packages. The latter is covered in a set of comparative exemplars in various packages in which basic features of analysis of audiovisual data are covered.
Background to exemplar research project and substantive research focus
In the context of increasing costs of face-to-face research, alternative technologies for data capture are of great interest to the social research community. Remote data collection via access grid node (AGN) technologies is one such development, and is the substantive topic of this exemplar research project. More information on the details of AGN technology can be found on the JANET website. AGN technology "can be thought of as an enhanced form of video teleconferencing, with cameras and microphones at each AGN site relaying images and utterances of the people at that site to other AGN sites [called ‘Nodes’]. There is no theoretical limit to how many sites can be linked, and participant numbers at each site are limited only by room size and technical configuration" (Fielding & Macintyre 2006: 1.1).
Previous work on access grid nodes and their use within field research (Fielding & Macintyre 2006) evaluated the use of AGNs for primary data collection in the context of "nonstandardised interviews and moderator-led group discussions" (2006: 1.4). The principal emphasis within this work was on communicative features, such as the facilitators and inhibitors in AGN-mediated interaction, including technical hitches and the significance of visual cues noted in video-teleconferencing. The substantive focus of the research was on lay participants in the criminal trial process. This exemplar research project differs from previous research in two key ways. Firstly, its substantive focus is on the use of AG technology to capture data about real-world interactions rather than interactions that take place within a research setting. In particular, it examines the interaction taking place within an AG-mediated business meeting. Secondly, and in the context of QUIC’s work, the project sought to provide insights into the process of analysing the multi-stream video data captured by the AGN technology using the CAQDAS package Transana. There are, therefore, substantive research questions regarding the use of AG technology in field research, but also method-driven research questions regarding the analysis of multi-stream data in Transana. These two sets of research questions are outlined below.
Substantive research questions in the exemplar project
- What is the nature of the exchange between participants in the meeting?
- Does the AG setting affect exchange between participants? If so, in what ways?
- What roles do the support teams (researchers, IT) play in the meeting?
- To what extent do the technical aspects (audio and visual setup) of the AG feature within the meeting? How do they feature?
- Nuancing the notion of co-presence, how does the physical grouping of individuals affect their communication, if at all?
- What are the implications of using AG-captured data for secondary analysis?
Method-driven research questions in the exemplar project
- What are the distinctive features of the Transana software package?
- On the basis of the QUIC team’s experience, what issues is the first-time user of Transana likely to encounter in the analysis of multi-stream audio-visual data?
- What are the possible analytical approaches to take in answering the above research questions?
Data analysed in the exemplar research project
The data used in this study come from one access grid-mediated business meeting between representatives from the Environment Agency and academics at the University of Surrey. The data are collected by two sets of video cameras. The first set is part of the AG system in which there are three front views of the meeting at both nodes, and one back view. The AG-captured data is the form of an amalgamation of 9 AG video feeds, with 3 front views of participants at each node, 1 view of slides projected by the AG system at each node, and 2 feeds showing the back views at each node. The second set of video cameras consists of stand-alone cameras, independent of the AG technology. These cameras film from the back of the room at both nodes, capturing what the participants at each node saw, and thereby providing analytical leverage in terms of examining the impact of the AG technology on the interaction. In total, the captured data from the meeting is 01:50:46 hours long.
This section is a reflective piece about lessons learnt, processes followed and sticking points encountered during an exemplar research project. It is not, therefore, a step-by-step guide on how to carry out an analysis, although it does contain certain procedural tips. For a review of basic features of Transana, see here. The researcher keeping this log had never used Transana prior to this piece of research. The log captures some of the learning process as it went along and is part of a group of pages that are based on an exemplar project in which an analysis of multi-stream video data was undertaken in Transana 2.42.
The data analysed by the exemplar project consisted of multiple video captures of a business meeting between academics at the University of Surrey and representatives of the Environment Agency. The participants were communicating via access grid (AG) technology (an advanced form of videoconferencing) and were physically located in Surrey and in Cardiff. The data themselves were captured by cameras that form part of the access grid system, but also by several stand-alone cameras. The project sought to examine the implications of using access-grid captured data for secondary analysis, as well as to gather empirical evidence on the ways in which this method of data collection may affect the data themselves.
Whilst the original research log was generated chronologically, as the research progressed, this page has been created by collating certain pertinent aspects from that raw log. It covers these aspects in some depth, providing technical detail. This is in contrast to the analytic processes section below, also related to the exemplar research project, which addresses various analytical steps more generally.
Structuring the database so as to make the most the software’s affordances
Transana 2.42 allows for sophisticated analysis of multi-stream audio visual data. The programme lets you structure audio visual data in various ways, provides facilities for multiple transcripts to be synchronised to this data, enables annotating and coding of the data, and offers various search and retrieve functions once data have been annotated and coded. It is tempting to import video files into Transana as soon as they are ready. Yet in order to make the most of Transana’s tools, it is advisable to take a moment to plan this step carefully.
In order to ensure effective use of the software, the first step is to think about the structure of the database that you will set up because the way this is done at the outset has implications later on. This includes deciding which audio visual data to import, as well as how to import it. I found two steps to be crucial here. Firstly, knowing your data, and secondly, being clear on your project aims. In my project, the analysis of multi-stream audio visual data captured during an Access Grid-mediated meeting, I had several audio visual data files that were potentially relevant to the research questions. I found that part way through the project I needed to go back and reacquaint myself with what each of these audio visual data files actually contained. This included examining when in the recording of the meeting each of the videos actually started, and, as a corollary to that, what was captured by each of them and how they differed. The exemplar research project was based on multiple videos of a single business meeting between academics at the University of Surrey and representatives of the Environment Agency. The participants were communicating via Access Grid technology , a sophisticated form of videoconferencing, with some of them located at the University of Surrey and some at the University of Cardiff. The meeting was captured by cameras that are part of the access grid system, and by other stand-alone cameras. I found that several of the video files from these cameras were very similar in terms of the analytical leverage they provided. I therefore carefully chose those files that provided different ‘views’ of the meeting.
The second crucial step was to maintain a clear idea at every stage of the aims and objectives of the research. Whilst each of my videos contained interesting data, not all of them were helpful to me in answering my research questions. I initially imported all of my audio visual files into Transana, yet I soon discovered the redundancies in some of them and realised that having more videos of the meeting in the database did not necessarily lead to more insight or analytical leverage. When multiple videos of the same event are imported and synchronised in Transana 2.42, the danger is that it becomes difficult to keep an overview of all them at the same time. So I focused on just three videos, one taken by the access grid technology, and two from stand-alone cameras. Additionally, there is a trade-off in terms of picture quality and size when multiple videos are displayed at the same time. Transana 2.42 allows you to choose which of the synchronised videos you would like to display, which means you can focus on just one, which addresses some of the costs of having multiple audio visual files synchronised. Nevertheless, my experience suggests that it is more effective and less confusing to import only the audio visual files you need to answer your research question(s), rather than getting carried away with the software’s ability to manage multiple files at once. This may well mean watching the videos outside Transana prior to importing them.
Once you are clear on your research questions and once you know your data well enough to be able to identify those files that will allow you to address these questions, the next step is to plan the structure of your database.
Transana asks you to structure your project from the beginning. As discussed in the overview of Transana’s basic features, the programme essentially allows for a 3-layered structure of data. At the highest level, groups of data are organised into ‘series’. A project may have multiple series, or multiple groups of data. The data themselves sit in what are called ‘episodes’. A series can hold multiple episodes. In Figure 1, a screen shot from my project, there are two series. One is entitled ‘AG data’, which houses only one episode (one video), and the other is entitled ‘AG Data synced with participant’s view’, which houses two episodes (two videos). So in a sense, ‘series’ bring together groups of ‘episodes’, and these may well be episodes you would like to compare. Every video file is attached to at least one transcript in Transana, which is the vehicle by which you take notes, code and generally analyse the video data. So what Transana calls an ‘episode’, really consists of video data and transcript data. The video data contained within one ‘episode’ can range from a single video stream to up to 4, synchronised, video streams. In Figure 1, the episode ‘triple stream synchronised view’ is attached to 3 transcripts: one ‘action’ transcript, one ‘descriptive sequences’ transcript, and one ‘verbatim’ transcript. In the exemplar project, the verbatim transcription served as a record of the spoken word during the meeting. The action transcript described the non-verbal interaction taking place, such as posture, direction of gaze etc., and the descriptive sequences transcript provided a rough overview what was happening in different sections of the meeting.
By asking you to decide how many ‘series’ your video data should be divided into, as well as asking you to name these series, Transana encourages you to structure your data. This can be useful, as in the case in my project, since it challenges you to think about what the aims of the project are. Which data are multiple exemplars of a similar phenomena? e.g. different camera angles of the same participant in a meeting. Provided they are temporally related, these video files might best be synchronised within one episode.
Another question I found important was to ask myself which video data should usefully be compared, e.g. videos from 3 meetings about the same topic. These video files might best be grouped within one ‘series’ but in different episodes. The advantage of doing so becomes clear once you come to running queries on your coded data, when all episodes within one series are easily compared using the series keyword sequence maps. Equally, data that are unrelated, or representative of different settings/ phenomena/ research aims might best be grouped within separate ‘series’, each with their own episodes within them.
The software-related requirement to think through the relationships between my videos and the underlying reasons for my analysis was very helpful since I already had a sense of what the important questions I wanted to explore were. There may, however, be cases in which this requirement to structure data early on runs contrary to the analytical approach the researcher seeks to adopt. If the researcher aims to allow meaning of and connections between data to emerge from the analysis (as in grounded theory approaches), then the Transana framework may impose unwanted structure upon the data. In such cases, it might be best to initially have one ‘total data’ series, in which each video is represented in a separate episode (and thus not hierarchically arranged). Subsequent to general analysis, groups that emerge can then be represented within new series and episodes that collate videos and even synchronise them. This would probably result in a very large database that represents both the unstructured and the structured data. From a practical point of view, this might be time-consuming since adding the video and audio files that constitute ‘episodes’ can take processing power and time.
Basics of opening, closing and saving a Transana database
It took me a little while to become comfortable with the opening, closing and saving of files in Transana. Upon opening the programme, you are immediately asked which database you want to open and you will be offered the option of opening the last one you worked on. If you want to start a new database, you need to provide Transana with a new name for that database. Recognising that that database does not exist, Transana asks you if you want to create a new one by that name. When you click yes, the new, empty, database is created, ready for you to import your files. Most changes you then make to that empty database are saved automatically, with the exception of changes to transcript files.
Whilst I quickly became used to the process of opening, closing and saving my database, I initially found it confusing. Thinking back, I think that is because I did not actually know where my Transana database was being saved. I am used to having to specify where I want to store my files, and indeed whether I want to save them at all. Transana’s approach was new to me since it not only automatically saves the database to a default folder on your hard drive (which you can locate by going to ‘options’, ‘program settings’), but is also assumes you always want to save most of what you have done. I found the latter useful once I got going with the analysis. However, at the beginning, when I was still finding my feet in terms of how to use the programme and trialling importing different files etc., I found myself constantly having to create new databases with new names, when really I just wanted to exit the programme without saving anything.
As a result of this initial inexperience in terms of opening, closing and saving the database, I found myself regularly exporting the databases I was working on and using that (which I believe is really a backup function) instead of simple saving. Transana functions as an external database system (Lewins and Silver, 2007) where the database does not hold the video files, but merely links to them on the computer. So essentially, a database is simply a series of links between documents and parts of documents (both textual and audio visual). Thanks to this, exporting and backing up the database under a new name at the end of every day did not take up too much hard drive space. I would then open a new database at the start of the next day, name it according to the day’s date, and use the ‘import database’ function to import the previous day’s database. This way I also always had a copy of the database as it had been the previous day, which, when the programme is constantly saving your work and you are prone to making a few misguided decisions along the way, is not a bad thing.
For those people wanting to avoid the regular export and import routines I was doing, it is advisable to open Transana and use the ‘options’, ‘programme settings’ dialogue box to set where you want the database, transcripts and audio waves to be saved. Then you can simply accept Transana’s prompt when you launch the programme of opening the database you last worked on. I would still recommend exporting the database once in a while, to back up your work.
Synchronising audiovisual files
Transana 2.42 allows you to synchronise up to 4 audio visual data files. I made use of this feature of the software and in doing so learnt two important things. The first of these relates to the order in which files need to be synchronised, and the second relates to the usefulness of the waveform (audio wave) in the synchronisation process.
The synchronisation of audio visual files calls for some planning. It is best to decide which files you want to synchronise first, and then to do the work of synchronising before undertaking any further analysis on that data. The clips that are subsequently created then include the corresponding sections of all of the desired audio visual files. I learnt that it is crucial to determine which of the audio visual data files starts first, so that the other files can then be anchored to that file in the synchronisation process.
In the actual process of synchronisation, the waveforms of the various videos helped me to match up the files accurately. These are essentially visual representations of the sound associated with the video (see Figure 2). The waveforms appeared in different colours, allowing me to distinguish them from one another. Roughly aligning the audio visual files using the audio was a good starting point. Thereafter, I looked out for matching spikes and dips in the waveforms and these helped me to align the files even more accurately.
One problem I came across is that Transana was not able to create a waveform for all of my files. The audio worked fine in each data file, but the visualisation of this was sometimes missing. It was in the context of accurately synchronising the audio visual files that I realised just how useful the waveforms could be.
A second sticking point I came across was that the quality of the audio in my various audio visual data files varied. This is a function of the different microphones that were used to capture data. I found that it was worthwhile to navigate to a section in all the videos where the audio was reasonable since this greatly facilitated the synchronisation process.
It is worth noting that Transana 2.42 allows the researcher to turn the audio on individual synchronised files on or off. I therefore chose to turn off the audios from all but one of the video streams, to minimise interference. I was conscious, however, that in doing so I prioritised one audio over the others and that this might have substantive implications for my analyses. In this case, I prioritised the audio captured by the access grid system over that captured by the stand alone cameras, since part of the research project was to consider the implications of using access grid-captured audio visual data for secondary analysis.
Making choices about tools for annotating, coding and retrieving data
Transana provides a variety of tools for annotating and coding data, as well for outputting and visualising analyses. These are outlined in the Transana review and described in more detail in terms of their use in this project on the page about analytical approaches to audio visual data in Transana, yet I felt it useful to include a short section on my experience of learning about these tools here.
I learnt how to use Transana in a step by step manner throughout the course of the research project. I largely went from deciding on a task, to figuring out how to solve it, to addressing the next task. Realistically, this is probably how a lot of people learn to use software. The advantages of this approach are seemingly obvious: firstly, you learn by doing, which means you are likely to retain more of the steps you learn, and secondly, you immediately get right down to starting the analysis and thereby feel like you are making progress. With hindsight, I still agree with the first of these two advantages – I do learn more effectively when I am working with my own data to solve a problem I have already formulated and thought about. Yet the second of these ‘advantages’ is perhaps less easy for me to agree with now, and I would advocate gaining an overview of the functionality of a piece of software before embarking on the analysis.
If I had had a sense of what the different tools in Transana 2.42 were prior to beginning the analysis, I would have been able to plan how to use these more effectively than I did. As it was, I learnt about the functionality of transcripts and became convinced that they were going to allow me to get at what I wanted to in the data. This lasted until I understood what notes could help me to do, upon which I substituted some of what the multiple transcripts were doing for me with what notes could do. Not long afterwards I figured out the affordances of using keywords more extensively, taking me away from notes for a while. Similar confusion occurred with respect to deciding which retrieval tools I wanted to rely on. Essentially, it was only once I had an overview of what the software could do that I was able to make informed decisions about which tools to use, when to do so and how. If I had done a training course at the start, or followed the very helpful tutorials on the Transana website, I might have saved myself a lot of time.
Deciding on units of analysis and their importance for clips and keywords
In my analysis I wanted to code sections of audio visual data. This is possible in Transana 2.42 by demarcating a given segment of interest using timestamps within the attached transcript(s) and by then creating a ‘clip’ from this segment. If there are multiple transcripts associated with the segment of audio visual data, all of these can be included with the ‘create a clip from multiple transcripts’ option. Multiple keywords can then be attached to the resulting clip. It is important to bear in mind, however, that keywords code the entire clip. It is not possible to have sections of a clip coded to a keyword. This had considerable repercussions for my analysis. I was interested in examining interaction between individuals and I wanted to be able to use fine-grained coding for this. I eventually decided that I needed to create clips for every speaker turn in my analysis. This required extensive time stamping and clip creation, which took a considerable amount of time. The lesson learnt here was that it is important to think about the unit of analysis in a study (in this case speaker turns) and to think through what the implications might be for analysis (in this case, very finely- graded time stamping and clip creation).To some extent, the more frequently a transcript is time stamped, the more flexible the clip creation and coding process is. For more discussion on the process of time stamping, please see the page on analytical processes in Transana.
Conclusions
I was able to carry out extensive analysis of multi-stream audio visual data during the course of the exemplar research project using the software tools available in Transana 2.42. Reflecting on my experience of Transana as a first-time user, there were a few technical aspects of the software-facilitated research process that I found important for the overall progress of the project.
Structuring the database so as to make the most of the software’s affordances included being clear about what the research aims were, as well as which of the data were likely to allow for effective answering of the research questions. My experience leads me to suggest that importing more data into a database does not necessarily lead to better analytical insight, particularly once the database gets crowed and it is difficult to maintain an overview.
Becoming comfortable with the basics of working with a Transana 2.42 database and its associated video files, transcripts and waveforms is an important first step which is worth exploring. This small time investment at the start would have ensured me greater peace of mind in terms of saving and backing up my work.
Importing audio visual data was simple in Transana, yet as is the case with all CAQDAS packages that offer this possibility, synchronising multiple video files accurately is challenging. Understanding the mechanics of the process is helpful, and making use of the visual aid that is the waveform is advisable.
Transana provided me with the tools necessary to carry out my analysis. However, the process of deciding which tools were most appropriate for which task was more arduous than it needed to be. I would recommend acquainting oneself with the basic function and features that allow for annotating, coding and retrieving data. This is likely to result in more effective project planning and use of researcher time.
Finally, understanding the importance of time stamping in relation to coding is essential. Finely time stamped transcripts result in more flexibility in terms of coding at a later stage. I would recommend time stamping at the time of transcription, with a particular awareness of the desired units of analysis within the project to act as a guide in terms of how finely time stamped the transcript should be.
This section was written by Sarah L. Bulloch.
The aim of this section is to provide insight into some of the analytical choices faced during the course of the exemplar project, and to reflect on the possible implications of the choices made. There were a number of potential analytic avenues open to the researcher and it is important to note that, as in all research, the choices made were shaped by a variety of constraints, including time. The processes documented here should, therefore, not be seen as ideal types, or recommendations. What is right for one research project may not be for another. Rather, this write-up of the analytic processes undertaken in the project provides a transparent and methodical account, thereby bringing into focus aspects of the research process that are critical to the outcomes, yet often under-represented in research dissemination.
What do we mean by ‘analytic processes’?
The definition of what constitute ‘analytic processes’ adopted here covers any steps taken that allow for the development of understanding regarding the phenomenon of interest on the basis of the data available. These steps include data preparation and segmentation, annotation and coding of data, as well as reflecting on and memoing about data and approaches adopted for the searching of patterns within the data, often facilitated by various ‘search and retrieve’ functions available in CAQDAS packages.
The role of analytic goals in the context of software tools
The way in which the analytic processes develop during the course of a research project should be informed by the project’s analytic goals, or research questions. These can be defined to a greater or lesser extent, depending on the methodological approach of the research. Where the research questions are clearly focussed, projects will often adopt more deductive forms of analysis, including thematic interests and coding schema that are pre-defined. Where the research questions are less focussed and more exploratory, the analytic processes and trajectories will often evolve throughout the project and annotation or coding will likely be inductive. Whether a deductive or inductive approach is taken within a project is likely to affect how a piece of software is used, as is discussed below. Lewins and Silver (2007) discuss this issue in more depth in their two chapters on coding.
This exemplar project began with a number of clearly defined aims that guided part of the analytic processes. In addition, as the analysis progressed, additional aims were adopted and existing aims were adjusted. In this sense, the process combined inductive and deductive approaches to the analysis (Layder 1998), and as a result, the exemplar project used a wide range of tools available within Transana 2.42. For more detail of the project set up, please see the log of research section above.
Transcripts in Transana 2.42 and their potential for analytic leverage
Every audio visual data file imported into Transana as an episode requires at least one transcript to be attached to it. The creation of this transcript is an automatic prompt in Transana 2.42. It is through this, and any additional transcripts, that the audio visual data file can be annotated and coded. As such, the transcript is a crucial part of analysis in Transana 2.42, however, the ways in which they are used as analytical tools is up to the researcher.
At the very least, the transcript is the vehicle within which time stamps are created, allowing the audio visual data to be segmented into sequential sections. In this capacity the transcript need not be populated with annotations or any writing at all. It can simply be a list of timestamps from which clips are created. This approach may be methodologically appropriate if the researcher feels it important to remain focussed solely on the audio visual, rather than rendering part of the analysis textual. For more reflection on this issue, see Silver and Patashnick (2011).
There are numerous analytical approaches beyond using the transcript as merely a vehicle for time stamp creation. A transcript can provide a textual record of the spoken word within the audio visual data (generally called a verbatim transcription) or it can provide a summary description of the content of a data file (what Dempster and Woods (2011) call ‘gisting’). These each provide different forms of analytical leverage. In the event that a project would benefit from multiple layers of analytical insights which transcripts can bring, Transana 2.42 allows for multiple transcripts to be attached to any one data file (or set of synchronised data files within the same episode), but only 5 of these can be opened at once.
Time stamps temporally link a transcript to the audio visual data. Therefore, if multiple transcripts are used the researcher has two options. First, all the transcripts can be linked to the audio visual data at the same points by using identical time stamps across all transcripts. Second, the various transcripts can carve up the audio visual data in different ways by using time stamps that are not identical. The choice between these two options is analytically relevant. Using identical time stamps throughout multiple transcripts indicates that the time stamped sections represent meaningful units within the analysis. This is the approach taken in the exemplar research project. The unit of analysis was interactions taking place within speaker turns. Thus each speaker turn was separately time stamped throughout the multiple transcripts. This approach prioritised the spoken interaction, taking this as the baseline. Non-verbal interactions taking place, captured by the action transcript, were organised according to the speaker turn they were associated with. Analyses that prioritise other types of interaction, or that chose not to prioritise one type over another, would potentially use transcripts differently, resulting in transcripts without identical time stamps.
Analytical approaches that benefit from identical time stamps across multiple transcripts call for a little more planning and are more deductive in approach. It is beneficial to create the identical time stamps across multiple transcripts all at once, rather than time stamping one transcript and then trying to recreate the same time stamps in another transcript. The various transcripts do not need to be complete or populated with the relevant text when these identical time stamps are created. Since only 5 transcripts can be opened at once, it makes sense to identically timestamp 5 to start off with. Transcripts can be deleted far more easily than they can be created, so having more than you might need available to start off with is prudent. As previously stated, transcripts can consist of lists of time stamps and once this structure is in place across each transcript, they be populated with whatever insights the researcher sees fit. Analytical approaches that do not require identical time stamps across transcripts can be more inductive. The researcher can create and amend time stamps as the research process goes along. Either way, it is helpful to think through what is more appropriate for the research at hand prior to embarking on time stamping.
Essentially, transcripts can be thought of as time-stamped annotations that can be used to record different layers of analytical thought. Where appropriate, they allow for inductive ways of working in so far as they can evolve over the course of the project and need very little planning (besides the possible benefit of replicating time stamps within multiple transcripts at the point where the first time stamps are created). They are, however, also crucial for the more deductive ways of working since they are the vehicle through which coding occurs.
In the exemplar project, the use of transcripts evolved throughout the project. Whilst the verbatim transcript fulfilled the same role from start to finish, additional transcripts changed from being spaces used for notes and reflections to being quite structured documents that were temporarily symmetrical (with identical time stamps). Towards the end of the exemplar project there were just two main transcripts in use: the verbatim transcript and the action transcript (which described non-verbal communication that coincided with each speaker turn). Other transcripts that had been used at the start became redundant. For example, the ‘descriptive sequences’ transcript, which had carved the video up into larger sections to help the researcher navigate through the data at the start of the project, became unnecessary as the research became more familiar with the data. Once the coding process started, the ‘descriptive sequences’ transcript also made the analysis slightly more clumsy in so far as it was not as finely time stamped as the other two transcripts. The repercussions of this were that every time a clip was created from all the open transcripts it was as long as the time stamped section in the ‘descriptive sequences’ transcript, rather than as short as the relevant sections in the other two transcripts. Given that a keyword is attached to the whole of a clip, this affected the finely graded coding plan for the project in which each speaker turn was to be coded separately. If the descriptive sequences transcript had been as finely time stamped as the verbatim and action transcripts, it may have been retained in the analysis, yet this process would have negated some of the benefits of a ‘descriptive sequences’ transcript in so far as the latter is created to loosely describe the data.
Once the coding had begun, the tool that ended up replacing the transcripts in terms of it being used for reflections and the recording of analytical insights etc, was the ‘notes’ function, discussed below.
Using the ‘notes’ function in Transana 2.42 and its potential for analytic leverage
The ‘notes’ function in Transana 2.42 provides a useful way of recoding thoughts and insights across a whole Transana database. These are similar in their function to ‘memos’ in other CAQDAS packages. It is possible to write notes about individual clips and whole collections of clips, whole transcripts (though not just sections of transcripts), episodes and series. Notes can be searched and retrieved via the ‘notes browser’, which displays them in an editable and exportable format. The notes browser helps to keep an overview of notes that are scattered around the database, which can be important if the database is large or there are many notes. Transana provides a function to date entries to notes, which allows these to be used as project diaries, charting thoughts as they develop over time.
A single note can only be attached to one item (e.g. a clip, a clip collection, a transcript etc.) but any one item can have several notes attached to it. This means that notes do not easily help to make connections between items in the database. Links can, however, be made between different episodes and series using codes (‘keywords’).
Analytically, notes performed an important function in the exemplar research project. They provided a space within which to record thoughts and ideas as they arose. As the project progressed, more and more notes were written about similar themes, and this suggested to the researcher that these themes were worth investigating further. Eventually the themes were turned into keywords (codes) and the whole dataset was explored again with these new insights in mind. So notes performed an important intermediary function within the project.
Using ‘keywords’ (codes) in Transana 2.42 and their potential for analytic leverage
Coding of audio visual data in Transana happens through the creation of ‘clips’ to which ‘keywords’ are attached. A clip is an extract of the audio visual data, along with its associated segment(s) of transcript(s). The creation of clips therefore relies heavily on the time stamps within transcripts. Whilst a clip must be demarcated by time stamps, it can include several time stamps within it, and so can be flexible in size. If clips are extracted with a particular theme in mind they can be organised into ‘collections’ titled according to that theme. If, however, the researcher does not want to confine a clip to any particular theme, he or she can either use the ‘quick clips’ function, which simply groups clips in a collection that is not specific to any theme, or, create a collection entitled ‘general clips’.
Clips can be as densely coded (attached to as many keywords) as is necessary. Keywords are attached using the ‘clip properties’ dialog box. This dialog box also contains the sections of transcript(s) attached to the clip.
A keyword must exist in the Keyword list prior to the coding of a section of data. It is not possible to create keywords ‘in vivo’. This means the researcher has to close down the clip he or she is coding and create the new keyword, and then return to the clip to code it. Keywords are organised into keyword groups. This structure is inherently a 2-level hierarchical one and the researcher is encouraged to develop categories of keywords within several keyword groups. If the analytical approach calls for it, it is possible to simply create many keywords within a single keyword group and thereby avoid hierarchy in coding.
In the QUIC exemplar project, coding was largely approached in a deductive manner, with codes created early on in the project to capture the dimensions that the research questions require. Within this structure, the project made use of the hierarchical nature of the coding scheme. Part way through the analysis several additional themes were discovered. In order to incorporate these into the clips that were already coded, it was necessary to go back and re-watch each clip to see if the new themes applied. This iterative process is common, even in projects that are largely deductive, as well as in those which do not use CAQDAS software.
Outputting and visualising tools in Transana 2.42 and their potential for analytic leverage
The value of analytical tools such as transcripts, notes and keywords depends to some extent on the options for searching and retrieving the insights developed and stored within each tool. The texts of both transcripts and notes can be searched within Transana, allowing the researcher to locate particular words or phrases. However, more complex Boolean searches (searches employing AND / OR / NOT functions) can only be performed on keywords attached to clips. Additionally, the coding of clips also leads to the largest choice of data visualisation tools in Transana. As was the case in the approach adopted by the QUIC exemplar project, transcripts and notes were very useful in terms of developing and recording insights throughout the research project. Yet most of the crucial insights were then transformed into keywords, and eventually resulted in coded clips. Whilst notes were widely used, transcripts were important since they formed a bridge between the data and searchable keywords in a way that notes cannot do, since the latter cannot be coded.
Keyword-related searches in Transana 2.42 vary in relation to the outputs they return. Searching for keywords across the whole database requires using the ‘search’ facility located in the ‘data’ window. This returns lists of clips from all series and episodes that are coded to the given keywords. These searches incorporate Boolean operators to allow for more complex combinations of searches.
Searches that provide visual outputs are well developed in Transana 2.42. There are a variety of types of visual outputs to choose from and these are exportable. However, in general these outputs are not very flexible in terms of being edited. For example, there is no option for zooming in or out, nor for the adjustment of font type or size. These searches can be narrowed down at the series level by either the ‘series keyword sequence map’, the ‘series keyword bar graph’ or by the ‘series keyword percentage graph’.
The first of these, the ‘series keyword sequence map’, provides a visual representation of keywords applied across the whole series. There are two options to choose from - the single-line series keyword sequence map and the multi-line series keyword sequence map. The first is represented in Image 1, and the second in Image 2. The multi-line sequence keyword map is more appropriate for projects in which a single clip has been coded to multiple keywords, since the single-line series keyword sequence map does not allow for overlapping keywords within a single clip.
Horizontally, there is a timeline of the data in the series, and vertically is a list of all the keywords applied to clips within the series. Coloured stripes indicate where a keyword has been applied to a particular section of the data in the series. It is possible to edit the series keyword sequence map using the filter function on the top left of the pop-up window. This allows the researcher to focus on particular keywords and to adjust the colours used to represent these.
The series keyword bar graph shows the distribution of keywords in relation to all the episodes in the whole series. It indicates how densely the various episodes have been coded, retaining the differences between the video lengths in each episode.
The series keyword percentage graph is similar to the series keyword bar graph, except that the length of audio visual data files represented across the series is normalised, allowing the researcher to compare coding of episodes that are of different lengths.
Searches can also be narrowed down to the episode level. Here the possible outputs include the ‘episode report’ and the ‘keyword map’.
An episode report is a textual document generated as an overview of the coding of each clip contained within an episode. It is exportable and amendable. The report closes with a summary table which details how many clips within the episode were coded which a particular keyword, and how many minutes of data, therefore, are coded to each keyword. This provides a basic quantitative descriptive overview of the data and its coding.
A keyword map is similar to a series keyword sequence map, except that it shows the coding across time within a single episode of audio visual data. The beginning and ending of the coloured stripes indicate the starts and endings of coded clips.
Searches can also take place at the collection level, where Transana 2.42 provides ‘collection reports’ and ‘collection keyword maps’, which are very similar to the ‘episode report’ and ‘episode keyword map’, except that they focus on the clips in a given collection, which can come from several different episodes across the database.
Conclusion
The extent to which, and ways in which a research project makes use of transcripts, annotations, codes, outputs and visualisations available in Transana 2.42 depends on the aims and objectives of the project. Each of these functions provide considerable analytical leverage if used appropriately. It is natural for there to be a time period in a project during which the aims of the research, and perhaps the resources available etc. are still being clarified. However, in order to maximise the analytical leverage provided by Transana 2.42, it is worth spending some time on this clarification, as well as on getting to know the software prior to starting the analysis.
Ethical considerations
Analysing audio visual data (e.g. video recordings, You Tube clips, etc.) has become a popular field of research but it can prompt questions with regards to ethics. The audio visual data collected under certain conditions can be used to understand behaviour, and thus can be beneficial to understand societal issues. However, Banks (2001) points out that the visual can be an instrument of surveillance and control because it creates a visual representation of the researcher’s subjects which can potentially affect the subject in various ways, and thereby raises ethical issues.
Additionally, audio visual data can easily be abused. Therefore, ethical regulations are necessary to protect the subjects’ rights so they are not objects of malpractice. For instance, this is of great importance for research projects that are interested in recording children’s behaviour e.g. playground behaviour, children in classroom situations etc. In this case consent has to be obtained from the appropriate figures of responsibility, such as the school, or Local Authority, as well as from the parents of each child who might be visually represented. This requires substantial preparation and planning. Parents must have the opportunity to require that their child’s image and voice is removed if the data is to be part of a publication. However, it should be kept in mind that any alteration may negatively affect the value of the research data.
This section looks at researcher-generated audio visual data and outlines implications and crucial steps that one should take into account when collecting, analysing and disseminating audio visual data.
Ethics committees and ethics applications
Ethics play a crucial role in any research project but become even more relevant for projects dealing with audio-visual data as the participants are visually presented and as such can easily be identified. Considerations of ethical research conduct should be part of the project from the very beginning as ethics are relevant at all stages. Although, under the Data Protection Act (1998), sensitive research information will remain restricted and confidential in the UK even without having been through a formal application of an ethics committee, the Act advises researchers to have all projects approved by an ethics committee. Within universities, research projects have to be approved via the university or departmental ethics committee (Wiles et al., 2010). In addition a range of professional associations provide guidance that can help researchers gain ethical approval for their research project. For example, the British Sociological Association has published a statement of ethical research practice as has the Social Research Association. The national research ethics service of the NHS might be useful for research projects dealing with health issues. The European Commission offers advice for ethics committees with regards to specific topic and countries.
Consent forms, anonymity and protection for both sides
During the collection of audiovisual data the use of consent forms is an essential part of ethical practice. The forms need to be fine tuned to the nature of the audiovisual data. Audiovisual data presents the challenge of what can be thought of as several layers of consent. Consent forms allow respondents to decide which parts of their data can be used for what purposes, and whether they require anonymity. In the context of audiovisual data, anonymity might require giving the participants the opportunity to have their picture distorted or even removed.
In negotiating these issues the QUIC project has used a variety of consent forms, some of which were based on examples available from ESDS Qualidata and the UK Data Archive, both at the University of Essex. The ESDS Qualidata website and the UK Data Archive provide useful information about consent and ethics in general as well as example sheets. The UK Data Archive gives general advice for consent and ethics as well as specific advice in regards to how to develop a consent form. For the example sheets, click on the link. Additionally, the UK Data Archive site has a section that focuses specifically on consent for audio-visual data.
A consent form is written permission in which the participant gives rights to the researcher to use his or her spoken word and/or visual representation for different research purposes, which have to be stated clearly in the form (Banks, 2001; Wiles et al., 2008). It is a contract between the researcher and the participant that has to be signed off by both and protects both under different circumstances. Thus, it is crucial to be precise and to include any possible aspects the research project might involve (e.g. further interviews that might be necessary, the use of additional researchers to analyse the data, access to the data in the future etc.).
Consent forms should be kept confidential in paper and electronic format and it is strongly recommended that participants receive a copy of the consent form and a project summary. The use of consent forms is especially important for dissemination and for further use of the data by third parties or archiving.
Advice and support: BSA, ESDS
A first step to get useful information about ethics in general is the ESRC’s Framework for research ethics and the British Sociological Association website and the statement of ethical practice. Although this document comprises relevant aspects for both textual and audio visual analysis some guidelines are more crucial for audio visual analysis than others. The BSA study group for visual sociology also provides useful information in regards to ethics and visual data. Note that all professional associations offer their own guidelines specific to the discipline in question.
The ESDS (Economic and Social Data Service) also offers advice and support for data creators and depositors on research project management, issues of confidentiality and consent and documentation for data of archiving. The Qualidata branch of the ESDS focuses on acquiring digital data collections of qualitative and mixed method contemporary research and UK-based classic studies.
Declaration of countries
Conducting research and collecting visual data in other countries can be challenging as different countries have specific regulations that can restrict researchers from getting access to data and information or even permission to interview people and video record them or take pictures. The European Commission for Research and Innovation offers further information about conducting research in other countries, in particular developing countries and health research.
Ethical conduct of researcher
The ethical conduct of the researcher (Pink, 2004) refers to the researcher’s own ethical understanding of his or her work and its context, which includes acknowledging different cultural values and behaviour as well as governmental regulations that might affect his or her research.
Ethics at different stages in the research process
There are many aspects that have to be taken into account when analysing audio visual data at different stages during the research process. A useful resource for the researcher is the ‘Research Ethics Guidebook’, which provides information about different aspects including visual methods. The list below presents the main stages where ethics considerations arise in social research projects.
1. Get approval for your research project
This might be the first time that you have to think about the data you are collecting and what possible implications this might have – who will be filmed? where? when? Which other institutions, partners might be involved, who would I have to ask for permission?
2. Approaching relevant bodies to get permission
Before collecting your data you need to have a list that shows you who needs to give permission. If multiple bodies are involved (e.g. schools, teachers, parents, etc.) then you need to draft a consent form (see more about consents forms below) for each of them.
3. Drafting consent forms
This can be a difficult stage as various aspects have to be taken into account. Here is a list that is by no means exhaustive but might be useful:
- Give participants the opportunity to withdraw from project at any time
- Make participants aware if there might be follow-up sessions / interviews
- Inform participants where this data will be used
- Let participants know who else will have access to the data
- Inform participants about the Data Protection Act (or locally–relevant legislation if outside the UK)
- Give participants the opportunity to have their image distorted or removed
- Give participants the opportunity to have their voice distorted or removed
- Give participants your contact details and have their contact details on the form
- Make sure that participants know what the project is about.
4. Storing and collecting consent forms
- Keep copies of the consent forms in paper and electronic form
- Provide a copy to participants.
5. Dissemination and archiving audio-visual data
- At some point it is likely that most researchers will want to publish their findings and include some of the data to visually illustrate their analysis. They might produce still images or even short movies to put them online. These aspects need to be considered at the outset and incorporated into the consent form.
- If you archive your data, for instance via the ESDS, then you need to be able to provide raw data and consent forms. The consent forms should state that this data will be archived (with e.g. ESDS). At the same time it is advised that you keep copies of your data on an external hard drive.
6. Example of Consent Form used by QUIC
- Consent form for Access Grid training session.
Analysing audio-visual data
This section provides commentary on aspects relating to the use of selected CAQDAS software packages to analyse audio visual data. Information on each individual software package should be read in conjunction with the comparative techniques for analysing data section below.
Note
This does not constitute a full description of software functionality or analytic strategies, but acts as a starting point for planning for the use of a particular software package and making comparisons with other software products. For more general reviews of functionality see choosing software or individual software websites.
The following materials are designed to showcase some of the main similarities and differences between selected CAQDAS packages in relation to how they handle and facilitate the analysis of video data with a view to supporting researchers in making informed choices.
Most CAQDAS packages now handle audiovisual data (AV data); that is, information presented in audible and visible form to the viewer such as recorded videos, movies, movie clips or archived film data. This section focuses on the analysis of video data; however most of the tips given can also be applicable to other forms of AV data. The material provided here is usefully read in conjunction with information on preparing audiovisual data for use in CAQDAS packages and ethical considerations in using and archiving audiovisual data. You may also find it useful to consult the materials which derive from the QUIC research project on analysing multi-stream video using Transana for reflections about using the software.
Some packages have had the analysis of audiovisual data as a central function from early on in their development or have been developed for this purpose, such as Transana, DRS (Digital Replay System) and Interact. For others, the capability of analysing audiovisual data is a later development, as is the case for ATLAS.ti, MAXQDA and NVivo.
The topics discussed here are derived from our own work (QUIC and the CAQDAS Networking Project) in analysing audiovisual data using CAQDAS packages and from the ‘frequently asked questions’ on the topic asked at our software training workshops or via our email / telephone helpline. There may be other aspects to consider, many of which are discussed in more detail in: Silver, C. and Patashnick, J. (2011).
Distinctions
Direct analysis, or via a written transcript?
Some software packages allow the direct analysis of AV data. This means that the process of coding happens directly via the video audio wave (NVivo 9, DRS) or video timeline (ATLAS.ti 6, Interact 9) rather than via a written document (Transana 2.4.2, MAXQDA 10). This can be particularly useful if the focus of analysis is the visual (e.g. what is ‘objectively’ seen to be happening, or non-verbal interactions between actors) and not on the verbatim content (e.g. what is being said, or a textual transcription thereof) (Silver & Patashnick 2011). However purely visual aspects may only be part of the analytic interest and there are many reasons why some sort of representation of audiovisual data is of value. Whatever the form, where a transcript is used, it needs to be anchored to the audiovisual data itself in order that both can be analysed concurrently. This anchoring can take place by inserting time stamps into the transcript. Timestamps are markers that segment the textual data and attach it to particular parts of the audiovisual data.
Number of transcripts
In generating transcripts of audiovisual data the question arises as to their purpose. Transcripts can take many forms, from a fully verbatim transcription of the audio, to a log of action. It can be challenging to integrate different purposes into one transcript and CAQDAS packages which allow the generation of multiple transcripts linked to one video or multiple videos offer additional flexibility (Transana 2.42, DRS, and to an extent NVivo 9 (in which each column of the transcript function can be used as an individual textual section referring to different aspects in relation to one video).
Single or multi-stream video?
Most software packages can play single video streams (ATLAS.ti 6, MAXQDA 10 and NVivo 9). However, Transana 2.42, DRS and Interact allow the use of multiple video streams and their synchronisation. This is of benefit where more than one perspective of an event or setting has been recorded and there is value in analysing them concurrently.
Analytic tools and techniques
Each software package offers slightly different ways of analysing audiovisual data. In most cases coding is the main means of marking and indexing data and standard CAQDAS tools can subsequently be used to interrogate data based on how they have been coded. See choosing software for more information on these, and other, generic CAQDAS tools. The nature of audiovisual data and the focus of the analysis will affect the extent to which coding tools are appropriate and sufficient, as will the complexity of data and its status within a research project (i.e. whether audiovisual data is of primary focus or supplements other forms of data). The amount of audiovisual data under consideration will affect the type of tools required with small amounts of data requiring the ability to be more precise in marking and annotating data as well as demanding a need to focus in on individual sequences. Large amounts of audiovisual data will often require a transcript of some sort. These issues are discussed in detail in Silver and Patashnick (2011).
Interface and data quality issues
Being able to manipulate video data in order to focus on particular aspects is important. Most of the software packages discussed here offer resize functions to make the video window bigger as required (Transana 2.42, DRS, ATLAS.ti 6, MAXQDA 10) whereas NVivo 9 for instance the video size can only be changed by changing the default setting. Even where resize options are available picture quality can be compromised when increasing proportions. Where there is a need to zoom in and out and picture quality is therefore paramount, it is worth investigating options for increasing picture quality to ensure the best visual outcome before work with the CAQDAS package commences. See information on preparing video for use in CAQDAS packages for further information on video editing software.
Waveform and timeline options
Each software package offers different ways of analysing AV data. Transana 2.42, NVivo 9 and DRS offer an audio wave which provides a fine-grained visual representation of the sound which can help pinpoint particular sections of interest throughout the video. Functions for zooming in and out of the waveform further enable small segments to be defined precisely. Although, ATLAS.ti 6 and MAXQDA 10 do not have an audio wave view, both packages offer a timeline function to define segments.
Choosing the most suitable software package for the analysis of audiovisual data will depend upon the requirements of an individual project, as well as the resources and constraints of the project. See below for our software reviews in relation to analysing audiovisual data.
For most of the CAQDAS packages reviewed here one short video has been produced to illustrate its use with audiovisual data. The video clip complements the written commentary, illustrating how selected tasks can be performed. The DRS and Transana reviews, however, include several shorter clips focused on particular aspects.
Each review page is structured as follows:
Overview and background
This section explains the initial idea of the CAQDAS packages and its main purpose and provides video links.
Interface
This section outlines the main windows when conducting AV analysis.
Distinctions
This section outlines key differences amongst different CAQDAS packages and refers to the distinctions outlined in this introduction but tailored to each CAQDAS package.
Beyond coding
This section mainly focuses on outputting findings by means of visual tools.
Other aspects (if applicable)
This section refers to additional functions specific to each software package if applicable.
References
This section provides links to further information specific to each of the packages.
This aim of the information on this part of the website is not to provide an exhaustive overview of functionalities but to focus on key aspects of different software packages in the context of analysing audio visual data.
1. Overview and background
ATLAS.ti was one of the first CAQDAS packages to enable the analysis of audio visual data. It was also a forerunner in handling geographical data, providing interactivity with Google Earth, and enabling effective connections between textual, audio, visual and geo data. For a broad overview of ATLAS.ti functionality see the review on choosing software. For more information on using ATLAS.ti with geographical data see the integrating geographical data section.
2. Interface
Most of the analysis of audio visual data in ATLAS.ti 6, takes place via four windows. Each of these can be resized, allowing the researcher to focus on different parts of the analysis at different stages.
The video window displays the audio visual data. Alongside, the ‘media track’ window allows data navigation such as pausing, starting and stopping the video, as well as segmenting the data into sections, or ‘quotations’. The ‘quotation manager’ window shows the list of segments of audio visual data that have been identified as analytically relevant. Quotations can be free-standing, annotated, coded and linked. The fourth window is the ‘code manager’, in which the project’s coding scheme is developed and from which codes are applied to quotations within the quotation manager. All four windows can be open at the same time, resized and relocated based on personal preference, allowing for a thorough overview of the analysis.
3. Distinctions
3.1. Direct analysis, or via a written transcript?
In ATLAS.ti audio visual data can be analysed without a written document, which allows the researcher to focus entirely on the visual. However, a textual document acting as a transcript can be linked to the audio visual file by using timestamps and the anchor function. Transcripts can either be generated within ATLAS.ti or using the bespoke transcription software, F4 and imported into ATLAS.ti. Upon importation the time-stamped transcript will be anchored to the video automatically.
3.2. Number of transcripts
ATLAS.ti 6 plays and displays one video in relation to one transcript at a time.
3.3. Single or multi-stream video?
ATLAS.ti 6 handles single stream videos. If the researcher wants to combine more than one video of a single event, this is best done in a video editing package outside of ATLAS, and the combined audio visual file can then be imported into ATLAS. Further information on this process can be found in the data preparation section above.
3.4. Analytic tools and techniques
ATLAS.ti supports a range of analytic approaches and enables both broad and in-depth analysis of audio visual data. Memos and quotations are key tools in segmenting, reviewing and reflecting upon audio visual data. Where a transcript is present and linked to the audio visual file, analysis can take place either directly (as described below) or via the transcript, as would be the case with purely textual data. In either case transcript and video remain linked and can be viewed and queried together.
Where no transcript is present, data must be segmented and analysed directly through the creation of quotations (or ‘clips’). These are created via the media track. Quotations can then be annotated and coded in the ‘quotation manager’ window. The creation of quotations is intuitive as the media track allows the demarcation of the start and end of the segment of interest. That audio visual data can easily be segmented, annotated and coded allows for the rapid development of broader analytical insights. Individual segments can be played-back in isolation for detailed consideration but more fine-grained analysis of short segments of data is generally easier if the segments can be extracted from the larger data file, which is not possible in ATLAS.ti. In addition, it can be difficult to mark the start and end point of quotations precisely on the ‘media track’, especially when video files are long.
The coding structure is developed within the code manager and codes can then be assigned to quotations within the quotation manager. Once coded, audio visual quotations can be treated like those deriving from any other type of data, and data searched and queried accordingly. See the ATLAS.ti review for more information on coding, searching and querying functionality.
3.5. Interface and quality issues
The windows in ATLAS.ti are flexible to move around and can be resized to the researchers’ needs. Increasing video size can enhance the analytical process where there is a need to focus in on particular aspects in detail. However, if videos are saved in small size resolutions or are of poor quality then resizing may only blur the picture further. It is therefore worth experimenting with data import.
3.6. Analysing AV data via audio-wave or ‘simple’ timeline function?
ATLAS.ti doesn’t have an audio wave (a visual representation of sound). This can compromise the accuracy of marking the parameters of quotations. This is of particular relevance in projects seeking to conduct a very fine-grained analysis of short segments of audio visual data.
4. Beyond coding
Visualising analytical processes by using the network tool
Visualising connections between data and concepts is inherent to qualitative data analysis. This is especially relevant for the analysis of audio visual data as it is not always possible to present audio visual clips as examples to underpin an argument or theoretical ideas in final reports. The network tool provides a range of tools to visually illustrate connections. For example, it enables non-linear associations to be tracked, coded clips to be grouped and re-played, and relationships to be organised, displayed and tested. Static versions of networks can be exported.
5. References
1. Overview and background
DRS is different to most of the CAQDAS packages included here as it is outcome of a research project based at the University of Nottingham, UK. DRS is an open-source, next generation CAQDAS package that can be downloaded freely from the internet. It is designed to help researchers integrate different forms of digital data e.g. textual, audio visual and quantitative data. The software is, at the time of writing, unsupported, but can still be downloaded.
2. Interface
Working in DRS involves managing multiple windows with which to organise and analyse data. The first window that will open when starting a new project is the ‘project browser’ window, which allows the researcher to manage the whole project. It contains all the data that is part of the project (files, users, deleted Items etc.). Whilst none of the analysis is actually done via this window, it provides a useful record of the work done on the project. In a group work situation, for example, the project browser facilitates the logging of which group member makes which changes to the project.
Analysis occurs from the ‘analysis browser’ window which provides a number of functions, in including importing transcripts, exporting transcripts, creating codes. It holds all the information about the data that is imported and subject to analysis in this project e.g. video files, transcripts, coding schemes, etc.
A key window within DRS is the ‘track viewer’, which provides the timeline for the data, linking between transcripts, any audio visual data and the coding schemes that are created. The track viewer is discussed in more detail below.
3. Distinctions
3.1. Direct analysis, or via a written transcript?
Any audio visual data that is to be coded needs to be linked to a textual document via time codes (discussed below).
Transcripts are displayed in a separate window, as are audio visual data files. The preparation of transcriptions can take place within DRS, but it is equally possible to import transcripts that have been prepared outside of the programme. If transcripts are to be synchronised with audio visual data, or indeed any other chronologically ordered data, such as heart rate over a certain time, the transcripts need to have timestamps embedded within them. These can be created within the DRS package, or by other transcription programmes, including F4.
Any new data that is imported into a DRS project can be linked to other data already in the project. This is an important feature of the software which facilitates the integration of many different kinds of data in a single project and allows tracking processes over time. This aspect is crucial for any DRS user as analysis is underpinned by the notion of time, and how different data are thereby related.
3.2. Number of transcripts
DRS can handle multiple videos and multiple transcripts, which can add additional layers of analytical leverage if they are used to record different types of insights throughout the project’s life course. However, each video and each transcript have their own windows, thus the number of windows to open and control increases as data are added.
All linked transcripts, audio visual data files and other data files in a single DRS project share a single timeline. This also means that they must all start at the same time point. This is manageable with one video and one transcript but can become challenging when more videos and transcripts or logs are added to the project and analysed synchronously.
3.3. Single or multi-stream video?
DRS is able to play multi stream video, which has to be synchronised in order to replay correctly. This synchronisation can happen within DRS. Alternatively, files can be combined in a video editing package outside of DRS, and the combined audio visual file can then be imported into DRS. Further information on this process can be found here . A strength of DRS is that other forms of data can also be synchronised to the video, such as data from heart beat monitors, for example.
3.4. Analytic tools and techniques
DRS can assist the researcher during different stages of a research project starting with broad initial investigation of the data to very fine-grained detailed analysis. Most of the fine-grained analysis happens via the ‘track viewer’. This represents the link, or synchronicity, between the transcript, the audio visual data and the coding schemes that are created. The track viewer provides the timeline for the data. Each track in the viewer can represent a different data source, or a different analytical theme (in the case of tracks that are dedicated to codes or annotations). It is important to be aware that in order to apply two codes to a single or overlapping section of data, two coding tracks are required. DRS allows the creation of a large number of coding tracks which can represent different aspects of a coding schema. Transcripts can be anchored to the timeline of the audio visual data, and codes can then be attached to a transcript which is linked to a particular part of the audio visual data. Parts of these coded textual sections are then visible in the track viewer, providing a visual sense of the build-up of analytical work on the data.
3.5. Interface and quality issues
The DRS interface is flexible and all windows can be resized and even moved around on the screen. This is important, since DRS produces many windows throughout a project, and an efficient means of managing them needs to be developed by individual researchers. During the analysis itself it might be useful to only work with the following windows open: the track viewer, the video window, the transcript window and the coding scheme window.
3.6. Analysing AV data via audio-wave or ‘simple’ timeline function?
DRS offers an audio wave and a track viewer (timeline) which are both very helpful when synchronising audio visual data with textual data and analysing different data types. DRS helps the researcher to complete this task by providing an adjustable timeline in the track viewer, where the researcher can zoom in and out for additional accuracy in matching times across various data sources.
4. Beyond coding
Beyond the ‘annotation viewer’ DRS also provides a concordance tool which allows the searching of textual strings and other lexical tags across data and codes. In order to get a visual overview of the analysis of data, it is possible to use the zooming in and zooming out function in the track viewer. This provides a picture of the coding density as well as any overlapping of codes across different coding tracks.
The annotation viewer is another window in DRS which lists all the annotations made to a particular piece of data. This is an important output in DRS, given that the version of the software currently available provides only limited code-based search and retrieve functions.
5. Other aspects
Differences in code creation and application
The code creation and application to data takes place through 3 windows outside the track viewer. The first is the Analysis browser, in which the code is created by creating a new ‘coding track’. Once this is done, DRS allows the researcher to elaborate on this coding track by opening a second window that holds the ‘coding scheme’ for that particular coding track. Here the researcher can set out the various elements of the coding scheme. For example, a coding scheme that aims to examine the kinds of experiences respondents have had could include a ‘negative’ experiences code and a ‘positive’ experiences code. These codes can then be attached to the data via the third window in the process – the track viewer. In order to show overlapping codes, a separate coding track needs to be created. This feature means that any coding schemes must only contain mutually exclusive categories of codes.
6. References
1. Overview and background
Audio visual analysis is a more recent add-on to MAXQDA, and whilst the programme manages it well, the primary focus of the software and its developments remain on the analysis of textual documents.
2. Interface
Analysis of audio visual data in MAXQDA 10 takes place via 5 main windows. Three of these also support textual analysis and so will be familiar to the user.
The ‘document system’ window lists and provides access to all of the documents that are part of a project, including textual documents, still images and audio visual data files. The ‘code system’ window displays the project’s coding scheme, which can be hierarchical and colour coded, and have memos linked. The third window, the ‘document browser’, displays the transcript associated with the audio visual data; all analysis of audio visual data in MAXQDA 10 takes place via a transcript. The two additional windows that are unique to audio visual analysis are the ‘video window’ and the ‘time stamp grid’. The ‘time stamp grid’ window has to be turned on separately and it details the length of the video, broken down into chosen segments, each demarcated by ‘time stamps’, as discussed below. These then form the smallest possible codable units of data.
3. Distinctions
3.1. Direct analysis or via a written transcript?
In order to analyse audio visual data in MAXQDA 10 a written document is required, which has to be time-stamped in order to by synchronised with the corresponding video. Transcription and time stamp creation can be done within MAXQDA 10. Alternatively, these tasks can be completed in the bespoke transcription software F4, which is freely downloadable from the audiotranskription.de website. MAXQDA 10 is able to read the timestamps created by F4 and the transcripts are easily imported and synchronised.
3.2. Number of transcripts
MAXQDA 10 allows linking one textual document to one video file. Analysis has to be made via the textual document. As such text remains the central analytic vehicle.
3.3. Single or multi-stream video?
MAXQDA 10 is not able to handle multi-stream audio visual data. If the researcher wants to combine more than one video of a single event, this is best done in a video editing package outside of MAXQDA 10, and the combined audio visual file can then be imported into MAXQDA 10. Further information on this process can be found in the preparing audio visual data for use with CAQDAS packages section.
3.4. Analytic tools and techniques
Linking the transcript to a video file by means of time stamps produces a ‘time stamp grid’ window, which allows comments to be added to individual time-stamped segments. As the audio visual data file is played, the relevant segments of the transcript are highlighted in succession. The comments added to each timed segment cannot themselves be coded, acting instead as annotations. Once coded, text segments linked to audio visual data can be treated like those deriving from any other type of data, and data searched and queried accordingly. See the MAXQDA review for more information on coding, searching and querying functionality.
3.5. Interface and quality issues
The video window in MAXQDA 10 can easily be resized and flexibly moved around. This is important as the video can only be analysed in conjunction with a transcript which might want to be viewed simultaneously to add text.
3.6. Analysing AV data via audio-wave or ‘simple’ timeline function?
MAXQDA 10 does not offer an audio wave instead it has a ‘simple’ timeline function that provides tools to manipulate the video, such as play, fast forward, rewind etc.
4. Beyond coding
Visualisation of segments and codes using MAXmaps
MAXQDA 10 provides a mapping tool called ‘max maps’ with which to visualise the connections between codes and sequences of audio visual data within the project. This helps to illustrate connections between particular themes. Any connections formed within the project can be reflected in a map.
5. Other aspects
MAXQDA continues to focus primarily on what has always been its main function: the analysis of textual data. MAXQDA might be particularly helpful to those who rely primarily on textual data but who want to complement this with a small amount of audio visual data. Those who are used to working with MAXQDA will find the analysis of audio visual data easy to get to grips with as the same principles and tools are used as for textual data.
6. References
1. Overview and background
Audio visual analysis is a more recent add-on to NVivo 8 and 9, which was initially developed as a tool for the analysis of textual data.
2. Interface
When working with audio visual data, analysis in NVivo9 takes place via three main panes – the navigation pane, the source pane and the detail pane. The first two function in the same as when analysing textual documents. The detail pane, however, is slightly different when working with audio visual data. It is divided into at least three sections. The top section shows the audio wave (visual representation of the audio that accompanies the video data), under which it is possible to display the coding stripes as these build up throughout the analysis. The bottom left section shows the video. If there is a textual transcript accompanying the audio visual data, the bottom right section of the detail pane shows this textual representation. An optional fourth section of the detail pane shows coding stripes that accompany the textual data.
In general, NVivo9 is not as flexible with its interface as some other CAQDAS packages, however it does offer a range of functions that are of great help with regards to audio visual analysis.
3. Distinctions
3.1. Direct analysis or via a written transcript?
NVivo 9 allows the researcher to code audio visual data directly, without having to work via a transcript. The analysis of the audio visual data takes place via the audio wave by selecting segments and coding or annotating those. In addition a transcript linked to a video can be generated within the software and annotated, coded etc. Indeed, the same audio visual file can be both directly analysed and via an associated transcript. Thought therefore needs to be given at an early stage as to the later implications of working in each way so as to develop an analytically meaningful and practically efficient process as inconsistency in approach can cause confusion.
3.2. Number of transcripts
NVivo 9 is not reliably compatible with other transcription software, thus it is advised to transcribe directly into a space offered next to the imported audio visual data. By default NVivo 9 offers columns to enter different information. However, these columns and the number of columns can be changed and customised, allowing each column could function as a ‘transcript’ of a different kind. Thus, multiple transcripts can be produced in relation to one video. However, each column refers to the same time stamped segment, which can be restrictive when working with multiple transcripts. Time-stamping the transcript is a fairly straight forward process.
3.3. Single or multi-stream video?
NVivo 9 is not able to handle multi-stream audio visual data. If the researcher wants to combine more than one video of a single event, this is best done in a video editing package outside of NVivo 9, and the combined audio visual file can then be imported into NVivo 9. It is worth remembering, however, that it is not possible to enlarge the video window from its default size, although it is possible to reduce its size. Therefore, the more videos are combined and then imported, the smaller the images will become, potentially making analysis difficult.
3.4. Analytic tools and techniques
Having an audio wave allows the researcher to analyse the video data without the need for a written transcript. When a segment of the audio wave is demarcated and codes (‘nodes’) are attached, these can be made visible by viewing coding stripes in the margin area. An audio wave that allows fine grained segmentation and analysis into meaningful units encourages researchers to start with the coding process. However, annotation can commence first and be followed by coding, although there is no automatic way to turn annotations into codes.
3.5 Interface and quality issues
The interface potentially has a significant impact with regards to the analysis of audio visual data since it is not possible to enlarge the video section of the detail pane, making it difficult to see the details of the video.
3.5. Analysing AV data via audio-wave or ‘simple’ timeline function?
Having an audio wave can be beneficial at different stages of an analysis. It facilitates navigation through the data by letting the researcher jump from one section to the other easily. It also provides a visual representation of the duration of the data, giving a sense of the location of a section of data within the whole video. The additional zooming function on the audio wave offers the researcher detailed ways of exploring data by allowing for focus on short segments of the audio visual data.
4. Beyond coding
Visualisation of analytical thinking processes using the MODEL function
NVivo 9 provides a ‘model’ tool with which to map out connections between data, annotations and codes. Rather than importing all the existing codes and data sources into the map automatically, NVivo9 requires the researcher to manually choose the elements of interest. Whilst this encourages critical thought with regards to deciding which elements to include and which to exclude within the data, it is also a time consuming process, requiring many clicks and layers of navigation within the software.
5. Other aspects
The default size of a video file that can be imported to and embedded within NVivo 9 is limited to 20 MB, although larger videos can remain ‘un-embedded’ and still be analysed.
6. References
1. Overview and background
Transana was developed specifically for the analysis of audio visual data. This is reflected in the terminology used throughout the programme, where data is organised according to ‘series’ and ‘episodes’, and where extracts of data are referred to as ‘clips’ and are brought together into ‘collections’. Linking to audio visual data files externally, Transana can handle a large number of data files in a single project, or ‘database’. The software’s search and retrieve functions are based on codes, or ‘keywords’ applied to clips (segments of the data) and these cut across all data in a database.
2. Interface
The Transana interface consists of four windows:
- Top right is the ‘video’ window, in which the video(s) are displayed
- Top left is the ‘visualisation’ window which displays the audio wave (referred to in Transana as the ‘waveform’) associated with the video, and, optionally, the codes (referred to in Transana as the ‘keywords’) attached to the data
- Bottom left is the ‘transcript’ window in which the single, or multiple, transcripts are displayed
- Bottom right, is the ‘data’ window, which displays the project (referred to in Transana as the ‘database’) structure, including the data itself, the keywords, clips (analytically relevant segments of data) and the clip search function.
The interface is flexible in so far as one can easily resize the different windows. There are also options in the drop down menus to adjust the interface to focus on video only, video and transcript only, or the audio and transcript only.
3. Distinctions
3.1. Direct analysis or via a written transcript?
Transana requires a textual document (e.g. transcript) to analyse audio visual data. In order to open, view and work with an audio visual data file, the audio visual data needs to be associated with one or more transcripts. Transcripts can be used in a variety of ways, depending on the needs of the project. A transcript can take the form of a full verbatim transcription of talk that takes place within the audio visual data. Alternatively, the transcript can take the form of short hand notes or annotations.
3.2. Number of transcripts
Transana supports the use of multiple videos and multiple transcripts for a single audio visual file (or ‘episode’ as Transana calls them). Up to 5 transcripts can be opened in relation to one episode at any one time. These multiple transcripts can provide different layers of analytical insights, allowing for a verbatim transcription, for example, as well as a transcription of the non-verbal interaction and a rougher timeline of what takes place in different sections of the audio visual data. Each transcript can be linked to the same audio visual file and be played-back concurrently. Individual transcripts can also be turned off as required.
Transcription can be done directly in Transana. The advantage of doing so is that timestamps can be incorporated during the transcription process, linking the textual transcription to the audio-visual data chronologically. However, it can also be done outside of the programme (we recommend a freeware programme called F4 for this purpose) and the file saved as an RTF file and then imported into Transana.
Timestamps should be set to mark sequences that are of analytical interest. Having timestamps allows extracting a sequence of interest as a clip.
3.3. Single stream video or multi stream video?
Transana can manage multi-stream video data. This is useful in cases where a particular event is captured from multiple angles and where the synchronisation of these multiple visuals provides additional analytical leverage. Up to four video files can be synchronised and analysed at the same time. These synchronised files can then share transcripts.
The process of synchronisation is dependent on one audio video file being designated as a sort of baseline file, to which the others are anchored, or ‘normed’. It is important that this baseline file is the one that starts first. If there is a large discrepancy between the start time of two audio video files, it may be advisable to use video editing software outside of Transana to tailor the videos to start at similar times.
3.4. Analytic tools and techniques
Transana requires at least one transcript to be associated with each audio visual data file and coding occurs via that transcript. In order to analyse audio visual data linked to a transcript timestamps have to be created in order to segment and code the data. The more frequently a timestamp is inserted, the more finely grained the subsequent clip creation, coding and searching can be.
Transana provides the tools for quite detailed analysis, but it must be remembered that a code, or ‘keyword’ is always applied to a whole clip, not subsections of it. This means that the reliance on timestamps is great, and detailed analysis requires many carefully created timestamps in order to extract many clips. (Keywords can only be attached to data if the data is turned into clips!) Keywords are organised hierarchically into ‘keyword groups’. If no hierarchy is desired, all keywords should be created under a single keyword group. Each keyword that is created can be accompanied by a definition, which can be amended at any time.
In addition to keywords, the researcher can record analytical insights gained throughout the project in the form of ‘notes’. These function similarly to ‘memos’ in other CAQDAS programmes and can be attached to groups of data (‘series’), individual audio visual data files (‘episodes’) as well as to transcripts.
3.5. Interface and quality issues
All windows in Transana can be resized and moved around. One should keep in mind that working with multiple transcripts might feel a bit crowded and so it is important to organise windows effectively.
3.6. Analysing AV data via audio-wave or ‘simple’ timeline function?
Transana provides an audio wave or ‘waveform’ which visually represents the audio component of the audio visual data. If there are multiple audios, Transana represents these with multiple waveforms of different colours. The waveforms are helpful in the synchronisation of audio visual data as detailed patterns in the waveforms can be matched. When individual clips are played-back the waveform is displayed for that segment only, allowing for more precise clip creation and finer analysis.
4. Beyond coding
Retrieving notes
Should the researcher want to retrieve all the notes written in a particular database, Transana provides the ‘notes browser’ function, found in the ‘tools’ menu. This calls up a pop-up window in which all the notes of the database are found. The notes browser provides the notes in an amendable format, as well as allowing these to be saved and printed. Notes cannot, however, easily be turned into keywords.
Transana’s search and retrieve functions are largely based around the use of keywords attached to clips. The only notable exception to this is the notes browser, which retrieves all the notes created across the database, as described above. These notes are not related to keywords.
Keyword searches
Keyword-related searches vary in relation to the outputs they return. Searching for keywords across the whole database requires using the ‘search’ facility located in the ‘data’ window. This returns lists of clips from all series and episodes that are coded to the given keywords. These searches incorporate Boolean operators to allow for more complex combination of searches.
Searches can be narrowed down at the series level by either the ‘series keyword sequence map’, the ‘series keyword bar graph’ or by the ‘series keyword percentage graph’.
The first of these, the ‘series keyword sequence map’ provides a visual representation of keywords applied across the whole series.
5. Other aspects
Working with multiple transcripts
When working with multiple transcripts the timestamps should be incorporated into more than one transcript simultaneously, even if all but one of these transcripts are otherwise empty at the start of the analysis. The reason for this is that if the researcher decides at a later stage to create another transcript and wants the two transcripts to be linked, and keywords to be attached to both transcripts, it is much easier to work from a pre-time-stamped transcript than to try to insert timestamps that match the first transcript. Time stamping multiple transcripts at the same time, therefore, acts as a structured canvas onto which additional layers of analytical insight can be painted. The advantage is that each of these additional layers is then anchored to the audio-visual data.
6. References
Summary
Most CAQDAS packages handle still images, audio files or video files. The following four packages provide most flexibility: ATLAS.ti, DRS, NVivo and Transana, but individual projects have specific needs and therefore it is recommended that the options are investigated in order to make an informed choice. We also recommend preparing multimedia files before assigning them to any CAQDAS package to increase compatibility and to work on copies within CAQDAS packages; storing the original files in a different location to avoid loss of data. If possible collect data and save it from the very beginning in a file format that suits most CAQDAS packages. Always be prepared to convert files, however, as the choice of CAQDAS package might involve downloading a suitable converter and editing program before starting to analyse the data.
Further reading
Ball, M.S., and Smith G.W.H. (1992). Analysing Visual Data, Qualitative Research Methods Series 24. California: Sage Publications.
Banks, M. (2001). Visual Methods in Social Research. London: Sage Publications.
Clukey, T. (2006). Capturing Your Sound: A Guide to Live Recording, Music Educators Journal 92: 26-32.
Dempster, P. G. and Woods, D.K. (2011). ‘The Economic Crisis through the eyes of Transana’, The KWALON Experiment: Discussions on Qualitative Data Analysis Software by Developers and Users, FQS, 12 (1), 16.
Fielding, N. and Macintyre, M. (2006). ‘Access Grid Nodes in Field Research’, Sociological Research Online, 11 (2).
Fielding, N. (2010). Virtual Fieldwork using Access Grid, Field Methods, 22 (3), 195-216, doi: 10.1177/525822XI0374277.
Hall, T.; Lashua, B.; and Coffey, A. (2008). Sound and the Everyday in Qualitative Research, Qualitative Inquiry 14 (6): 1019-1040.
Hindmarsh, J. (2008). Distributed video analysis in social research. In Fielding, N.G., Lee, R.M. and Blank, G. (Eds.), The SAGE handbook of online research methods, London: Sage. pp.343-361.
Layder, D. (1998). Sociological Practice: Linking Theory and Social Research, Sage.
Lewins A., and Silver C. (2007). Using Software in Qualitative Research: A Step-by-Step Guide. Sage Publications. London.
Loizos, P. (2006). Video, Film and Photographs as Research Documents. In Hamilton, P. Visual Research Methods, Chapter 68, Vol 4, 289.
Mazzoni, D., and Dannenberg, R.B. (2002). A Fast Data Structure for Disk-Based Audio Editing, Computer Music Journal 26: 62-76.
Modaff, J.V. and Modaff, D.P. (2000). Technical Notes on Audio Recording, Research on Language & Social Interaction 33: 101-118.
Pink, S., (2004). Doing Visual Ethnography. London: Sage Publications.
Rivers, C.; Silver, C.; and Woodger, N., (2011), ‘Camera Set-up, Image Placement and Interactive Devices in Virtual Learning Environments: Increasing the Feeling of Co-Presence and Interactivity in Access Grid mediated sessions’, In Proceedings of the 9th International Conference on Education and Information Systems, Technologies and Applications: EISTA 2011, Orlando, FL, USA, 19-22 July 2011.
Rose, G., (2005). Visual Methodologies. London: Sage Publications.
Schnettler, B. and Raab, J. (2008). Interpretive visual analysis: Developments, state of the art and pending problems. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 9 (3), 31.
Silver, C. and Patashnick, P. (2011). ‘Finding Fidelity: Advancing audiovisual analysis using software’ The KWALON Experiment: Discussions on Qualitative Data Analysis Software by Developers and Users, FQS, 12 (1), 37.
Stanczak, G. (Ed.) (2007). Visual research methods: Image, society and representation. London: Sage.
Stockdale, A. (2002). Tools for Digital Audio Recording in Qualitative Research, Social Research Update 38.
Wiles, R., Coffey, A., Robison, J., Prosser, J. (2012). Ethic Regulation and Visual Methods: Making visual research impossible or developing good practice, Sociological Research Online, 17 (1). 1-17.
Wiles, R., Prosser, J., Bagnoli, A., Clark, A., Davies, K., Holland, S., Renold, E. (2008). Visual Ethics: Ethical issues in visual research. ESRC. National Centre for Research Methods. Review Paper. Accessed on 31.8.2017.
See the ‘Links’ and ‘Bibliography’ pages, providing related topics and sources.
- Duncan Bradley’s resource on audio in NVivo - this resource is outdated).
- JANET(UK)
- JISC Digital Media - Jisc’s most extensive resource on digital media in the social sciences.
- Transana documentation
- Transana website.